Pytorch 基础
https://pytorch.org/tutorials/beginner/basics/intro.html
大多数机器学习工作流:
通过 Pytorch 基础部分的内容,读者可以完整的走完一整个MachineLearning的工作流,若读者对其中某个环节不理解或感兴趣,针对这些工作流中的每一个环节都有相关的扩展阅读链接。
我们将使用 FashionMNIST 数据集训练一个神经网络,该神经网络预测输入图像是否属于一下类别之一:T恤/上衣、裤子、套头衫、连衣裙、外套、凉鞋、成山、运动鞋、包包、靴子。(是个多分类任务)
快速入门
https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.html
本节会快速走完一个机器学习多分类的Demo,以此快速了解流程中必要的基本ML相关API。
处理数据 Pytorch 中有两个用于处理数据的子库 torch.utils.data.DataLoader 和 torch.utils.data.Dataset.Dataset。顾名思义,Dataset 存储样本及其相应的标签,并将 DataLoader 可迭代对象包装在 Dataset 中。
1 2 3 4 5 import torchfrom torch import nnfrom torch.utils.data import DataLoaderfrom torchvision import datasetsfrom torchvison.transforms import ToTensor
通过上面的引用(import),我们可以发现:Pytorch 中有非常多的子库,这些子库专注于某一特定的领域,例如: TorchText , TorchVision , 和 TorchAudio , 这些所有子库中都包含相应的数据集。
本次教程中我们使用 TorchVision 数据集。
该 torchvision,.datasets 模块包含 Dataset 来自现实世界中的视觉图像数据,最经典的有:CIFAT,COCO(full list here )
本次教程中我们使用 FashionMNIST 数据集。每个 TorchVison 下的 Dataset 都包含两个参数:transform 和 target_transform 分别用来修改样本 与打标签 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 training_data = datasets.FashionMNIST( root = "data" , train = True , download = True , transform = ToTensor(), ) test_data = datasets.FashionMNIST( root = "data" , train = False , download = True , transform = Totensor() )
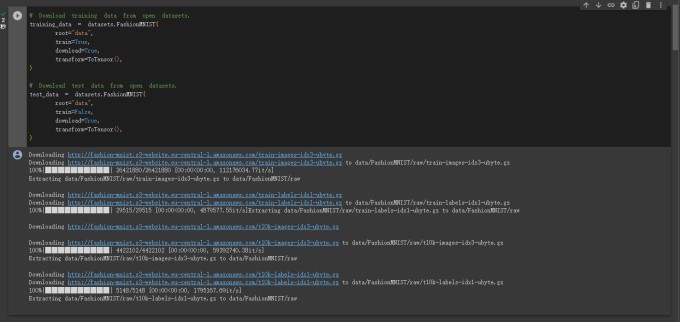
下图是在 colab 中运行上面程序块的输出结果:
至此为止,通过上面的工作,我们将 Dataset 作为参数传递给了 DataLoader 。同时封装了相关数据集作为一个可迭代的对象,支持自动批处理、采样、洗牌(shuffling)、和多进程的数据加载。
下一步中,我们定义 batch_size = 64 ,即 dataloader 可迭代中的每个元素都将返回一批含有64个特征的标签。
1 2 3 4 5 6 7 8 9 10 batch_size = 64 train_dataloader = DataLoader(tarain_data, batch_size = batch_size) test_dataloader = DataLoader(tast_data, batch_size = batch_size) for X, y in dataloader: print (f"Shape of X [N, C, H, W]: {X.shape} " ) print (f"Shape of y []: {y.shape} {y.dtpye} " ) break
输出:
1 2 Shape of X [N, C, H, W]: torch.Size([64, 1, 28, 28]) Shape of y: torch.Size([64]) torch.int64
关于 loading data in PyTorch 的详细说明
构建模型 为了在 Pytorch 中定义神经网络,我们创建一个继承自 nn.Module 的类。
我们通过 __init__ 函数定义神经网络的层,并指明数据如何通过 forward 函数进入神经网络层。
在设备允许的情况下,推荐使用GPU来加速神经网络的运算操作。
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 device = ( "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu" ) print (f"Using {device} device" )class NeuralNetwork (nn.Module): def __init__ (self ): super ().__init__() self.flatten = nn.Flatten() self.linear_relu_stack = nn.Sequential( nn.Linear(28 *28 , 512 ), nn.ReLU(), nn.Linear(512 , 512 ), nn.ReLU(), nn.Linear(512 , 10 ) ) def forward (self, x ): x = self.flatten(x) logits = self.linear_relu_stack(x) return logits model = NeuralNetwork().to(device) print (model)
打印结果:
1 2 3 4 5 6 7 8 9 10 11 Using cpu device NeuralNetwork( (flatten): Flatten(start_dim=1, end_dim=-1) (linear_relu_stack): Sequential( (0): Linear(in_features=784, out_features=512, bias=True) (1): ReLU() (2): Linear(in_features=512, out_features=512, bias=True) (3): ReLU() (4): Linear(in_features=512, out_features=10, bias=True) ) )
在 PyTorch 中构建神经网络
这一部分是对‘构建模型’部分的一点补充说明,也是 PyTorch 官网教程中的扩展阅读部分
神经网络是由多个对数据进行操作的层/模型组合而成的。torch.nn 命名空间几乎已经提供了构建一个神经网络所需要用到的所有模块 。
所有模块都在 PyTorch 下的子块 nn.Module 中提供。
基于这样的结构化嵌套模块,整个神经网络可以自由的进行构建和管理复杂的架构。
在上面的代码块中,我们通过 NeuralNetwork 函数定义了一个神经网络模型 model。
为了使用该模型,我们将输入数据传递给它。这个操作将执行 forward 操作和一些后台操作 。
请记住:不要直接使用 model.forward() !
通过输入操作调用模型,最后将返回一个二维张量,其中 dim = 0 对应于每个类别的 10 个原始预测输出,dim = 1 对应与每个输出的单个值。
我们可以通过 nn.Softmax 模块实例传递对结果预测的概率来进行最终预测概率的判断。
1 2 3 4 5 X = torch.rand(1 , 28 , 28 , device = device) logits = model(X) pred_probab = nn.Softmax(dim = 1 )(logits) y_pred = pred_probab.argmax(1 ) print (f"Predicted class: {y_pred} " )
打印结果:
1 Predicted class: tensor([7], device = 'cuda:0')
模型层 Model Layers 分解 FashionMNIST 模型中的各层。为了说明这一点,我们通过获取一个包含 3 张大小为 28*28 的小批量图像样本,看看当数据传递到网络时会发生什么。
1 2 input_image = torch.rand(3 , 28 , 28 ) print (input_image.size())
打印输出:
nn.Flatten 初始化 nn.Flatten 层,将每个2D 28*28 图像转换成包含 784 个像素值的连续数组(保持小批量尺寸(dim = 0))
1 2 3 flatten = nn.Flatten() flat_image = flatten(input_image) print (flat_image.size())
打印输出:
nn.Linear 线性层模块 通过输入的权重w和偏差值b进行线性变换。
1 2 3 layer1 = nn.Linear(in_features = 28 *28 , out_features = 20 ) hidden1 = layer1(flat_image) print (hidden1.size())
打印输出:
nn.ReLU 非线性激活函数可以在模型的输入输出之间创建复杂的映射关系。激活函数通过引入非线性的变换帮助神经网络学习各种现象。
在实例模型中,我们在线性层之间使用ReLU激活函数。但还有其他激活函数可以在模型的线性层中间作为激活函数使用,详情参考:激活函数-wiki
1 2 3 print (f"Before ReLU: {hidden1} \n\n" )hidden1 = nn.ReLU()(hidden1) print (f"Aftr RelU: {hidden1} " )
打印输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Before ReLU: tensor([[ 0.4158, -0.0130, -0.1144, 0.3960, 0.1476, -0.0690, -0.0269, 0.2690, 0.1353, 0.1975, 0.4484, 0.0753, 0.4455, 0.5321, -0.1692, 0.4504, 0.2476, -0.1787, -0.2754, 0.2462], [ 0.2326, 0.0623, -0.2984, 0.2878, 0.2767, -0.5434, -0.5051, 0.4339, 0.0302, 0.1634, 0.5649, -0.0055, 0.2025, 0.4473, -0.2333, 0.6611, 0.1883, -0.1250, 0.0820, 0.2778], [ 0.3325, 0.2654, 0.1091, 0.0651, 0.3425, -0.3880, -0.0152, 0.2298, 0.3872, 0.0342, 0.8503, 0.0937, 0.1796, 0.5007, -0.1897, 0.4030, 0.1189, -0.3237, 0.2048, 0.4343]], grad_fn=<AddmmBackward0>) After ReLU: tensor([[0.4158, 0.0000, 0.0000, 0.3960, 0.1476, 0.0000, 0.0000, 0.2690, 0.1353, 0.1975, 0.4484, 0.0753, 0.4455, 0.5321, 0.0000, 0.4504, 0.2476, 0.0000, 0.0000, 0.2462], [0.2326, 0.0623, 0.0000, 0.2878, 0.2767, 0.0000, 0.0000, 0.4339, 0.0302, 0.1634, 0.5649, 0.0000, 0.2025, 0.4473, 0.0000, 0.6611, 0.1883, 0.0000, 0.0820, 0.2778], [0.3325, 0.2654, 0.1091, 0.0651, 0.3425, 0.0000, 0.0000, 0.2298, 0.3872, 0.0342, 0.8503, 0.0937, 0.1796, 0.5007, 0.0000, 0.4030, 0.1189, 0.0000, 0.2048, 0.4343]], grad_fn=<ReluBackward0>)
nn.Sequential nn.Sequential是一个有序的模块容器。数据按照定义好的方式顺序的通过当前模块。seq_modules .
1 2 3 4 5 6 7 8 seq_modules = nn.Sequential( flatten, layer1, nn.ReLU(), nn.Linear(20 , 10 ) ) input_image = torch.rand(3 , 28 , 28 ) logits = seq_modules(input_image)
nn.Softmax Softmax激活函数通常用在最后一个线性层,用来返回对数区间介于 [-infty, infty] 中的原始值,这些值最终被传递给 nn.Softmax 模块。
Softmax 激活函数将对应输出区间范围缩放在 [0, 1] 之间,表示模型对每个类别的预测概率 。其中,dim 中所有参数指示值求和应该为 1 。
1 2 softmax = nn.Softmax(dim = 1 ) pred_probab = softmax(logits)
模型的参数 神经网络往往非常的复杂,在整个网络的构建过程中,如果可以便捷的将每个部分表示出来,对于训练过程中的优化和修改相对的权重与偏差等都会有非常大的帮助。
子类化 nn.Module 模块可以帮助我们解决这个问题,该模块会自动跟踪模型对象中定义的所有字段,并使用模型的 parameters() 函数或 named_parameters() 函数方法访问所有参数。
在本次示例中,我们遍历每个参数,并预览它们的所有数值参数。
1 2 3 4 print (f"Model structure: {model} \n\n" )for name, param in model.named_parameters(): print (f"Layer: {name} | Size: {param.size()} | Values : {param[:2 ]} \n" )
打印输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Model structure: NeuralNetwork( (flatten): Flatten(start_dim=1, end_dim=-1) (linear_relu_stack): Sequential( (0): Linear(in_features=784, out_features=512, bias=True) (1): ReLU() (2): Linear(in_features=512, out_features=512, bias=True) (3): ReLU() (4): Linear(in_features=512, out_features=10, bias=True) ) ) Layer: linear_relu_stack.0.weight | Size: torch.Size([512, 784]) | Values : tensor([[ 0.0273, 0.0296, -0.0084, ..., -0.0142, 0.0093, 0.0135], [-0.0188, -0.0354, 0.0187, ..., -0.0106, -0.0001, 0.0115]], device='cuda:0', grad_fn=<SliceBackward0>) Layer: linear_relu_stack.0.bias | Size: torch.Size([512]) | Values : tensor([-0.0155, -0.0327], device='cuda:0', grad_fn=<SliceBackward0>) Layer: linear_relu_stack.2.weight | Size: torch.Size([512, 512]) | Values : tensor([[ 0.0116, 0.0293, -0.0280, ..., 0.0334, -0.0078, 0.0298], [ 0.0095, 0.0038, 0.0009, ..., -0.0365, -0.0011, -0.0221]], device='cuda:0', grad_fn=<SliceBackward0>) Layer: linear_relu_stack.2.bias | Size: torch.Size([512]) | Values : tensor([ 0.0148, -0.0256], device='cuda:0', grad_fn=<SliceBackward0>) Layer: linear_relu_stack.4.weight | Size: torch.Size([10, 512]) | Values : tensor([[-0.0147, -0.0229, 0.0180, ..., -0.0013, 0.0177, 0.0070], [-0.0202, -0.0417, -0.0279, ..., -0.0441, 0.0185, -0.0268]], device='cuda:0', grad_fn=<SliceBackward0>) Layer: linear_relu_stack.4.bias | Size: torch.Size([10]) | Values : tensor([ 0.0070, -0.0411], device='cuda:0', grad_fn=<SliceBackward0>)
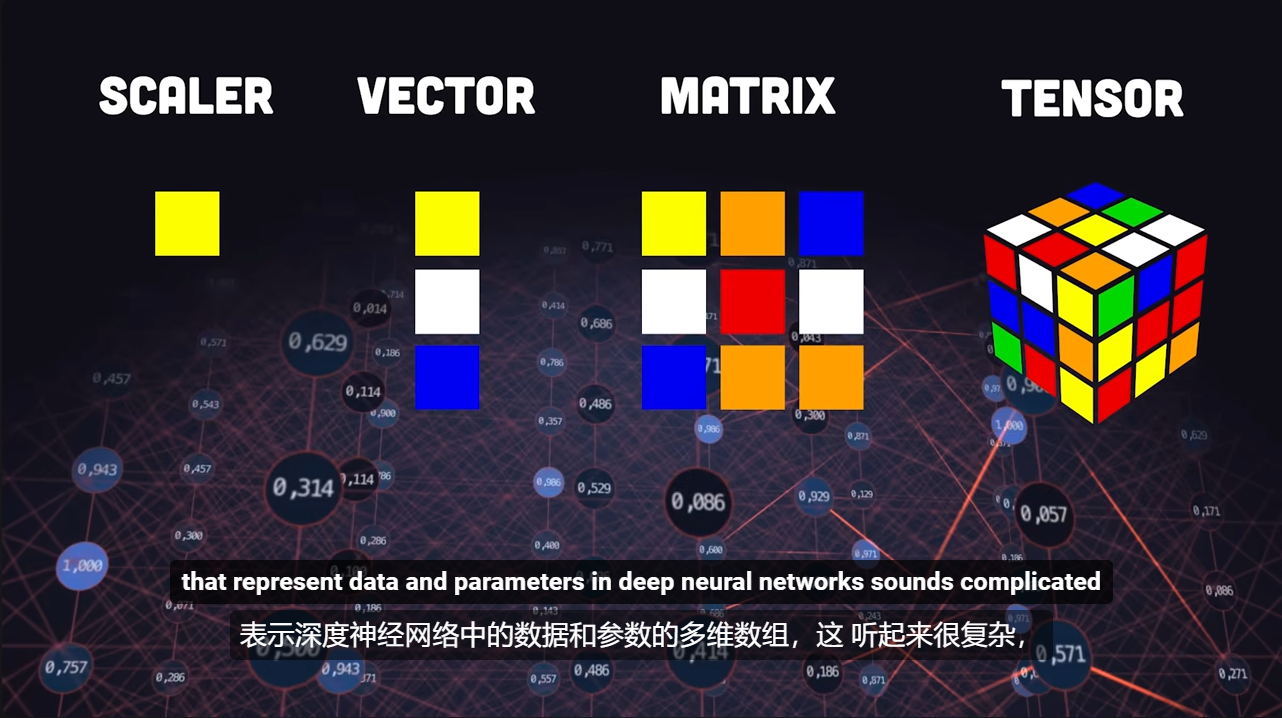
张量 Tensor 通过一张图初步了解常见的多维空间数据的命名方式(来源:PyTorch in 100 Seconds )
Tensor 又称 张量,是一种专门的数据结构,与数组和矩阵非常相似。在 PyTorch 中,我们使用张量对比模型的输入和输出以及模型的参数进行编码。
Tensors 类似于 NumPy 中的ndarrays,不同之处在于张量可以在 GPU 或其他硬件加速器上运行。事实上,张量和 NumPy 数组通常可以共享相同的底层内存,从而消除了复制数据的需要。
张量也针对自动微分进行了优化。
1 2 import torchimport numpy as np
初始化张量 一般可以通过如下方式初始化 Tensor:
直接通过数据创建
通过NumPy创建
通过继承另一个Tensor的形状和数据类型
使用随机值或常量
下面分别进行介绍:
直接来自数据 张量可以直接从已有的数据中创建,数据类型是自动推断的。
1 2 data = [[1 , 2 ], [3 , 4 ]] x_data = torch.tensor(data)
来自另一个 Tensor 新建的张量保留参考张量的部分参数(形状,数据类型 ),除非用显式的方式直接覆盖。
1 2 3 4 5 x_ones = torch.ones_like(x_data) print (f"Ones Tensor: \n {x_ones} \n" )x_rand = torch.rand_like(x_data, dtype = torch.float ) print (f"Random Tensor: \n {x_rand} \n" )
打印输出:
1 2 3 4 5 6 7 Ones Tensor: tensor([[1, 1], [1, 1]]) Random Tensor: tensor([[0.8823, 0.9150], [0.3829, 0.9593]])
使用随机值或常量 shape 是张量维度的元组表达式。在下面的函数中,它决定了输出张量的维度:
1 2 3 4 5 6 7 8 9 shape = (2 , 3 , ) rand_tensor = torch.rand(shape) ones_tensor = torch.ones(shape) zeros_tensor = torch.zeros(shape) print (f"Random Tensor: \n {rand_tensor} \n" )print (f"Ones_Tensor: \n {ones_tensor} \n" )print (f"Zeros_Tensor: \n {zeros_tensor} " )
打印输出结果:
1 2 3 4 5 6 7 8 9 10 11 Random Tensor: tensor([[0.3904, 0.6009, 0.2566], [0.7936, 0.9408, 0.1332]]) Ones Tensor: tensor([[1., 1., 1.], [1., 1., 1.]]) Zeros Tensor: tensor([[0., 0., 0.], [0., 0., 0.]])
张量的属性 Tensor 的属性描述了它们的形状 数据类型 存储它们的设备
tensor.shapetensor.dtypetensor.device
1 2 3 4 5 tensor = torch.rand(3 , 4 ) print (f"Shape of tensor: {tensor.shape} " )print (f"Dtype of tensor: {tensor.dtype} " )print (f"Device of tensor: {tensor.device} " )
打印输出:
1 2 3 Shape of tensor: torch.Size([3, 4]) Datatype of tensor: torch.float32 Device tensor is stored on: cpu
张量的操作 科学计算是深度学习领域的根本!PyTorch提供了 100+ 张量运算操作,包括算术运算、线性代数运算、矩阵运算(转职、索引、切片)、采样等。
PyTorch 中的所有逻辑运算都可以通过GPU进行加速运算
1 2 3 if torch.cuda.is_available(): tensor = tensor.to("cuda" )
类似 NumPy 的索引和切片操作 1 2 3 4 5 6 Tensor= torch.ones(4 , 4 ) print (f"First row: {tensor[0 ]} " )print (f"First column: {tensor[:, 0 ]} " )print (f"last column: {tensor[..., -1 ]} " )tensor[:, 1 ] = 0 print (tensor)
打印输出:
1 2 3 4 5 6 7 First row: tensor([1., 1., 1., 1.]) First column: tensor([1., 1., 1., 1]) Last column: tensor([1., 1., 1., 1]) tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]])
Tensor 之间的连接 torch.cat 可以用于连接指定维度的张量,拥有同样功能的另一个算子是 torch.stack_ (参考:torch.stack_ )。
1 2 t1 = torch.cat([tensor, tensor, tensor], dim = 1 ) print (t1)
张量的算术运算 1 2 3 4 5 6 7 8 9 10 11 12 13 14 y1 = tensor @ tensor.T y2 = tensor.matmul(tensor.T) y3 = torch.rand_like(y1) torch.matmul(tensor, tensor.T, out = y3) z1 = tensor * tensor z2 = tensor.mul(tensor) z3 = torch.rand_like(tensor) torch.mul(tensor, tensor, out = z3)
打印输出:
1 2 3 4 tensor([[1., 0., 1., 1], [1., 0., 1., 1], [1., 0., 1., 1], [1., 0., 1., 1]])
单一元素张量 如果你有一个单一元素的张量,例如希望通过将张量的所有值聚合为一个值,那么可以使用 item() 将其转换为 python 数值:
1 2 3 agg = tensor.sum () agg_item = agg.item() print (agg_item, type (agg_item))
打印输出结果:
原地操作(不通过返回的方式进行原地修改) 将结果存储在操作数中的操作成为原地操作。它们由 _ 后缀表示。例如:x.copy() 、 x.t_() ,都将直接修改 x。
1 2 3 print (f"{tensor} \n" )tensor.add_(5 ) print (tensor)
打印输出:
1 2 3 4 5 6 7 8 9 tensor([[1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.], [1., 0., 1., 1.]]) tensor([[6., 5., 6., 6.], [6., 5., 6., 6.], [6., 5., 6., 6.], [6., 5., 6., 6.]])
Tensor 和 Numpy 二者转换 位于 CPU 位置上的 Numpy 数组与 Tensor 可以共享同一个底层的内容空间,更改一个 tensor 会同时修改另一个 tensor 。
Tensor2NumPy_array 1 2 3 4 t = torch.ones(5 ) print (f"t: {t} " )n = t.numpy() print (f"n: {n} " )
打印对比结果(t 代表 tensor;n 代表 numpy):
1 2 t: tensor([1., 1., 1., 1., 1.]) n: [1. 1. 1. 1. 1.]
下一步,改变 tensor 中的值,同时观察 NumPy 中值的变化:
1 2 3 t.add_(1 ) print (f"t: {t} " )print (f"n: (n)" )
打印对比结果(t 代表 tensor;n 代表 numpy):
1 2 t: tensor([2., 2., 2., 2., 2.]) n: [2. 2. 2. 2. 2.]
NumPy_array2Tensor 1 2 n = np.ones(5 ) t = torch.from_numpy(n)
NumPy 数组中的更改回反映在张量(tensor)中
1 2 3 np.add(n, 1 , out = n) print (f"t: {t} " )print (f"n: {n} " )
1 2 t: tensor([2., 2., 2., 2., 2.], dtype=torch.float64) n: [2. 2. 2. 2. 2.]
数据集的相关操作 从代码的架构设计上考虑,无论是出于可读性考虑还是出于代码逻辑的模块化管理考虑,我们都希望数据集代码与模型训练代码分离。
在数据预加载上,PyTorch 提供了两个功能函数 torch.utils.data.DataLoader 和 torch.utils.data.Dataset 分别读取预加载的数据和自己的数据。
Dataset 存储样本和对应的标签,并在 DataLoader 范围内包装成一个可迭代对象 Dataset 以便轻松访问样本。
在 PyTorch 函数库中预先提供好了很多可供预加载的数据集(例如:FashionMNIST),这些数据集借助 torch.utils.data.Dataset 子类化,并实现位于特定数据的函数。它们可用于对模型进行原型设计和基准测试。可以通过如下链接访问:Image Datasets ,Text Datasets ,Audio Datasets
数据加载 下面例子是从 TorchVision 加载 Fashion-MNIST 数据集的示例。Fashion-MNIST 由 60000 个训练样本和 10000 个测试样本组成。每个示例都包含一个 28*28 灰度图像和一个来自 10 个类之一的关联标签。
我们通过如下几个参数,对 FashionMNIST Dataset 数据集进行加载:
root 是存储训练/测试数据的根目录train 指定训练或测试数据集download = TRUE 允许从互联网上搜索并下载数据集,前提是 root 路径下的数据集文件不存在transform 和 target_transform 分别执行 标定特征 和 标注转换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import torchfrom torch.utils.data import Datasetfrom torchvision import datasetsfrom torchvision.transforms import ToTensorimport matplotlib.pyplot as plttraining_data = datasets.FashionMNIST( root = "data" , train = True , download = True , transform = ToTensor() ) test_data = datasets.FashionMNIST( root = "data" , train = False , download = True , transform = ToTensor() )
数据集迭代和数据可视化 使用 Datasets ,我们可以实现像 Python 中列表那样的手动索引 training_data[index]。
使用 matplotlib 可视化训练数据集中的样本进行展示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 labels_map = { 0 : "T-Shirt" , 1 : "Trouser" , 2 : "Pullover" , 3 : "Dress" , 4 : "Coat" , 5 : "Sandal" , 6 : "Shirt" , 7 : "Sneaker" , 8 : "Bag" , 9 : "Ankle Boot" , } figure = plt.figure(figsize = (8 , 8 )) cols, rows = 4 , 4 for i in range (1 , cols * rows + 1 ): sample_idx = torch.randint(len (training_data), size(1 ,)).item() image, lable = training_data[sample_idx] figure.add_subplot(rows, cols, i) plt.title(lables_map[label]) plt.axis("off" ) plt.imshow(img.squeeze(), cmap = "gray" ) plt.show()
打印输出:
创建自定义的数据集 自定义数据集必须含有三个函数:
__init____len____gititem__
通过下面这个示例实现了解相关函数的使用方法。
FashionMNIST 图像存储在目录 img_dir,其自身的标签单独存储在CSV文件 annotations_file 中
先看代码块部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import osimport pandas as pdimport torchvision.io as read_imageclass CustomImageDataset (Dataset ): def __init__ (self, annotations_file, img_dir, transform = None , target_transform = None ): self.img_labels = pd.read_csv(annotations_file) self.img_dir = img_dir self.transform = transform self.target_transform = target_transform def __len__ (self ): return len (self.img_labels) def __getitem__ (self ): img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0 ]) image = read_image(img_path) label = self.img_labels.iloc[idx, 1 ] if self.transform: image = self.transform(image) if self.target_transform: label = self.target_transform(label) return image, label
_init _ init 作为初始化函数,在实例化 Dataset 对象时运行一次。
我们初始化包含图像 、注释文件 和两个转换的目录
labels.csv 文件的展示效果如下所示:
1 2 3 4 tshirt1.jpg, 0 tshirt2.jpg, 0 ...... ankleboot999.jpg, 9
1 2 3 4 5 def __init__ (self, annotations_file, img_dir, transform = None , target_transform = None ): self.img_labels = pd.read_csv(annotations_file) self.img_dir = img_dir self.transform = transform self.target_transform = target_transform
_len _ len 函数返回数据集中的样本数。
1 2 def __len__ (self ): return len (self.img_labels)
_getitem _ getitem 函数从给定索引目录的 idx 处返回数据集中的样本。
根据索引,它识别图像在磁盘上的位置,使用 read_image,从 csv 数据中检索相应的标签self.img_labels,调用它们的转换函数(前提是支持转换),并在元组中返回张量图像和相应的标签。
1 2 3 4 5 6 7 8 9 def __getitem__ (self ): img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0 ]) image = read_image(img_path) label = self.img_labels.iloc[idx, 1 ] if self.transform: image = self.transform(image) if self.target_transform: label = self.target_transform(label) return image, label
准备数据并使用 DataLoader 进行训练 检索 Dataset 数据集的特征,并一次标记一个样本。
在训练模型的过程中,我们通常希望通过“小批量”的方式传递样本,在新一轮 epoch 下数据 reshuffle(洗牌) 减少模型过拟合,并使用 Python 中的 multiprocessing 函数来加快数据检索的速度。
DataLoader 是一个可迭代的对象,它通过一个简单的 API 为我们抽象了这种复杂性。
1 2 3 4 from torch.utils.data import DataLoadertrain_dataloader = DataLoader(training_data, batch_size = 64 , shuffle = True ) test_dataloader = DataLoader(test_data, batch_size = 64 , shuffle = True )
遍历 DataLoader 通过上面的步骤,我们已经将数据集加载到了 DataLoader 并可以根据我们的需要来遍历该数据集。
后续程序中每一次迭代都会返回一批 train_features 和 train_labels,每批结果中都包含 batch_size = 64 特征和标签。
在上面代码块中,我们指定了 shuffle = True ,在我们遍历了所有批次后,数据会被洗牌(目的是为了更细粒度地控制数据加载顺序,可参考Samplers )
1 2 3 4 5 6 7 8 9 train_features, train_labels = next (iter (train_dataloader)) print (f"Feature batch shape: {train_features.size()} " )print (f"Labels batch shape: {train_labels.size()} " )img = train_features[0 ].squeeze() label = train_labels[0 ] plt.imshow(img, cmap = "gray" ) plt.show() print (f"Label: {label} " )
转换 数据的格式不总是按照训练机器学习算法所需要的格式出现的,因此我们需要通过转换
所有 TorchVision 数据集都具有两个参数:
transform 用于修改标签target_transform 接受包含转换逻辑的可调用对象
在 torchvision.transforms 中提供了几个开箱即用的转换格式。
FashionMNIST 特征采用 PIL Image 格式,标签为整数。
在训练任务开始前,我们需要将特征处理为归一化之后的张量。
为了进行这些转换,需要使用 ToTensor 和 Lambda 函数方法。
1 2 3 4 5 6 7 8 9 10 11 import torchfrom torchvision import datasetsfrom torchvision.transforms import ToTensor, Lambdads = datasets.FashionMNIST( root = "data" , train = True , download = True , transform = ToTensor(), target_transform = Lambda(lambda y: torch.zero(10 , dtype = torch.float ).scatter_(0 , torch.tensor(y), value = 1 )) )
打印输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz to data/FashionMNIST/raw/train-images-idx3-ubyte.gz 0%| | 0/26421880 [00:00<?, ?it/s] 0%| | 65536/26421880 [00:00<01:12, 362364.70it/s] 1%| | 229376/26421880 [00:00<00:38, 680532.51it/s] 3%|2 | 786432/26421880 [00:00<00:11, 2194389.90it/s] 7%|7 | 1933312/26421880 [00:00<00:05, 4185622.75it/s] 17%|#6 | 4423680/26421880 [00:00<00:02, 9599067.02it/s] 25%|##5 | 6717440/26421880 [00:00<00:01, 11175748.57it/s] 34%|###4 | 9109504/26421880 [00:01<00:01, 14174360.51it/s] 44%|####3 | 11567104/26421880 [00:01<00:01, 14358310.56it/s] 53%|#####2 | 13959168/26421880 [00:01<00:00, 16463421.66it/s] 62%|######2 | 16449536/26421880 [00:01<00:00, 15864345.49it/s] 71%|#######1 | 18776064/26421880 [00:01<00:00, 17449238.29it/s] 81%|######## | 21397504/26421880 [00:01<00:00, 16758523.84it/s] 90%|########9 | 23691264/26421880 [00:01<00:00, 18055860.39it/s] 100%|##########| 26421880/26421880 [00:01<00:00, 13728491.83it/s] Extracting data/FashionMNIST/raw/train-images-idx3-ubyte.gz to data/FashionMNIST/raw Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw/train-labels-idx1-ubyte.gz 0%| | 0/29515 [00:00<?, ?it/s] 100%|##########| 29515/29515 [00:00<00:00, 327895.25it/s] Extracting data/FashionMNIST/raw/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz 0%| | 0/4422102 [00:00<?, ?it/s] 1%|1 | 65536/4422102 [00:00<00:11, 363267.41it/s] 5%|5 | 229376/4422102 [00:00<00:06, 683985.17it/s] 19%|#8 | 819200/4422102 [00:00<00:01, 2304448.10it/s] 33%|###3 | 1474560/4422102 [00:00<00:00, 2999709.36it/s] 83%|########2 | 3670016/4422102 [00:00<00:00, 7976134.77it/s] 100%|##########| 4422102/4422102 [00:00<00:00, 5985529.02it/s] Extracting data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz 0%| | 0/5148 [00:00<?, ?it/s] 100%|##########| 5148/5148 [00:00<00:00, 39473998.16it/s] Extracting data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw
ToTensor() ToTensor 将 PIL 图像 或 NumPy ndarray 转换为 FloatTensor. 并在[0., 1.] 范围内缩放图像的像素空间。
Lambda 转换 Lambda 函数允许任意用户定义 lambda 函数。在这里,我们定义了一个函数,将整数转换为 one-hot 编码的张量。
Lambda首先创建一个大小为10(我们数据集中的标签数量)的零向量,并调用 scatter_ 函数在索引 y 上分配标签 value = 1。
1 2 target_transform = Lambda(lambda y:torch.zeros( 10 , dtype = torch.float ).scatter_(dim = 0 , index = torch.tensor(y), value = 1 ))
阅读延伸:torchvision.transforms API
(核心内容)自动微分(TORCH.AUTOGRAD) 在训练神经网络时,常用的算法是反向传播 。在该算法中,参数(模型权重)根据损失函数相对于给定参数的梯度 进行调整。
为了计算这些梯度,PyTorch 有一个内置的用于自动计算微分方程的引擎,称为 torch.autograd .
它支持任何计算图的梯度自动运算。
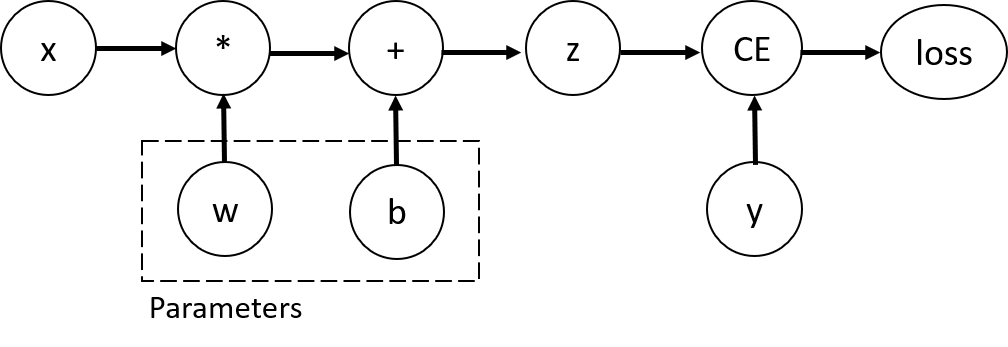
下面距离一个最简单的单层神经网络,其中包含输入 x、参数 w 和 b,以及一些损失函数。可以在 PyTorch 中按以下方式定义它:
1 2 3 4 5 6 7 8 import torchx = torch.ones(5 ) y = torch.zeros(3 ) w = torch.randn(5 , 3 , requires_grad = True ) b = torch.randn(3 , requires_grad = True ) z = torch.matmul(x, w) + b loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
张量、函数、计算图 上一小节的代码框中实现的损失函数计算流程如下图所示:
在上面网络中,w 和 b 是我们需要优化的参数。因此,我们需要能够计算这些变量损失函数的梯度。
为了做到这些点,我们设置了这些张量的 requires_grad 函数来定义其属性。
设置张量的值有两种方式:一种是在生成张量的时候使用 requires_grad 进行初始化设置;另一种是在后续使用 x.requires_grad_(True) 函数。
用来构造计算图的函数实际上是类 Function 的对象。该对象指导如何计算正向函数,以及如何在反向传播步骤中计算其导数。对向后传播函数的引起存储在张量的属性中的 grad_fn。您可以在PyTorch的官方文档 中找到更多信息 Function。
1 2 print (f"Gradient function for z = {z.grad_fn} " )print (f"Gradient function for loss = {loss.grad_fn} " )
打印输出:
1 2 Gradient function for z = <AddBackward0 object at 0x7d800ac85840> Gradient function for loss = <BinaryCrossEntropyWithLogitsBackward0 object at 0x7d800ac85ea0>
梯度计算 为了优化神经网络中的参数权重,我们需要计算损失函数相对于参数的导数,即我们需要在固定 x 和 y 值的情况下,求出 $\frac{\partial loss}{\partial w}$ 和 $\frac{\partial loss}{\partial b}$。
为了求出上面的导数,我们需要调用函数 loss.backward(),然后从 w.grad 和 b.grad 中检索权重和偏置的数值。
1 2 3 loss.backward() print (w.grad)print (b.grad)
打印输出:
1 2 3 4 5 6 tensor([[0.3287, 0.0101, 0.0988], [0.3287, 0.0101, 0.0988], [0.3287, 0.0101, 0.0988], [0.3287, 0.0101, 0.0988], [0.3287, 0.0101, 0.0988]]) tensor([0.3287, 0.0101, 0.0988])
禁用梯度追踪 默认情况下,所有张量都在 require_grad = True 跟踪其计算历史并支持梯度计算。但是,在某些情况下,只想将模型应用于默写输入数据时,即我们只想通过网络进行前向计算。我们可以通过将计算代码加上 torch.no_grad() 还书,用来停止跟踪计算。
1 2 3 4 5 6 z = torch.matmul(x, w) +b print (z.requires_grad) with torch.no_grad(): z = torch.matmul(x, w) + b print (z.requires_grad)
另一种方法是在张量上使用 detach() 方法:
1 2 3 z = torch.matmul(x, w) + b z_det = z.detach() print (z_det.requires_grad)
考虑要禁用梯度跟踪的情况:
将神经网络中的某些参数标记为冻结参数
为了优化计算速度,在只进行前向传播时禁用梯度跟踪的选项
计算图部分扩展阅读 (留白,前面的区域以后再探索吧~)
可选阅读:张量梯度 和 雅阁比积(Jacobian_Products) (留白,前面的区域以后再探索吧~)
(重要)优化模型参数 在拥有了模型和数据之后,就可以通过优化数据参数来训练、验证和测试我们的模型了。训练模型是一个带带过程,每次迭代中,模型都会对输出进行*猜测 *,计算其猜测中的误差,计算其猜测中的误差(损失),收集误差对参数的导数(上一节中进行的工作),并使用梯度下降这些参数。
更详细的视频讲解,可以参考 backpropagation from 3Blue1Brown
先决条件代码 超参数 优化循环 全过程数据跟踪 保存、加载和使用模型 保存/加载模型权重 通过模型的形状参数进行保存/加载 在 PyTorch 中保存和加载常规 Checkpoint 介绍 设置 步骤 1.导入加载数据所需要的库 2.定义和初始化神经网络 3.初始化优化器 4.保存常规检查点 5.加载常规检查点 从 Checkpoint 中加载 nn.Module 的技巧 活用 torch.load(mmap = True) 活用 load_state_dict(assign = True) 结论